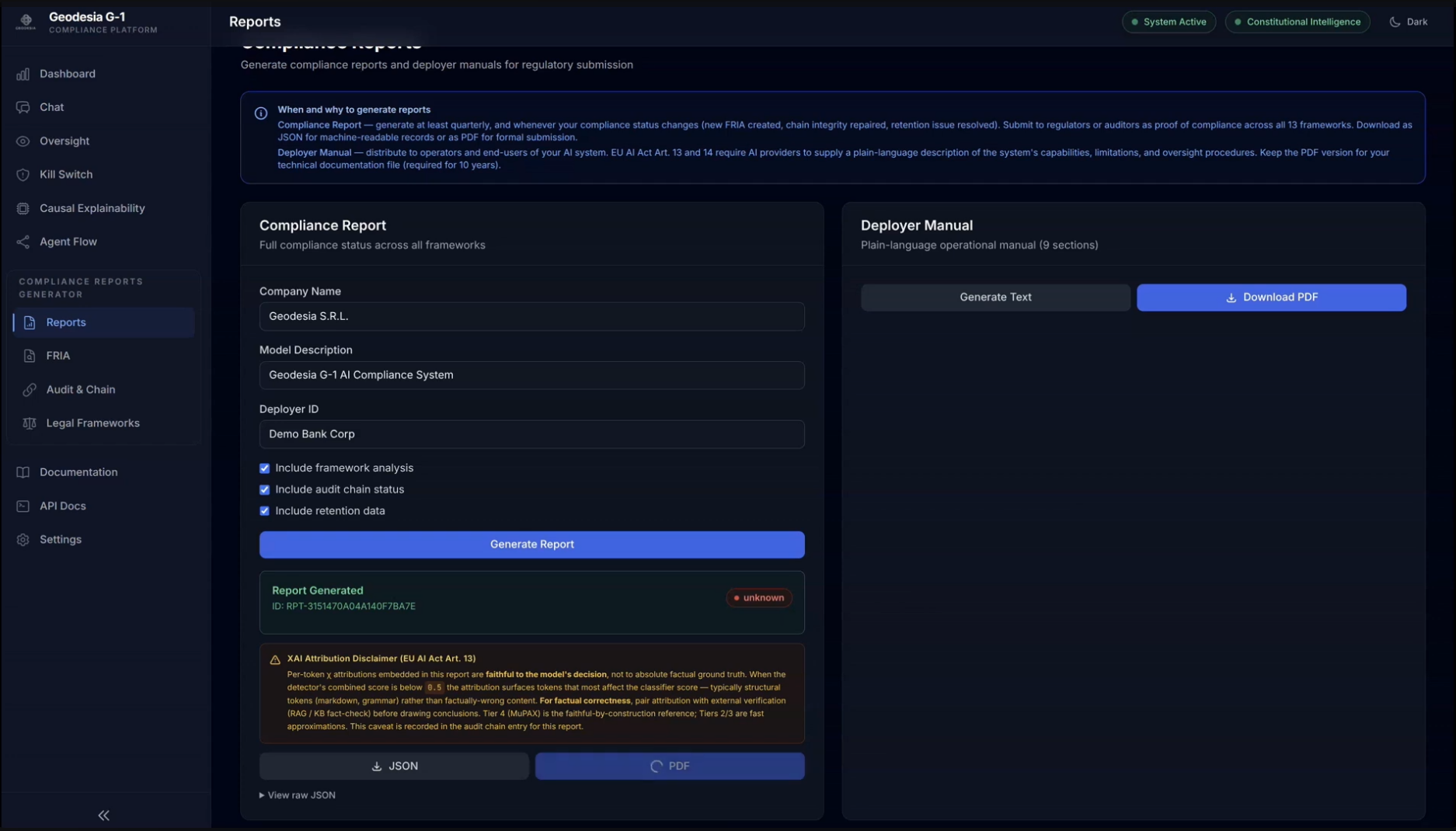
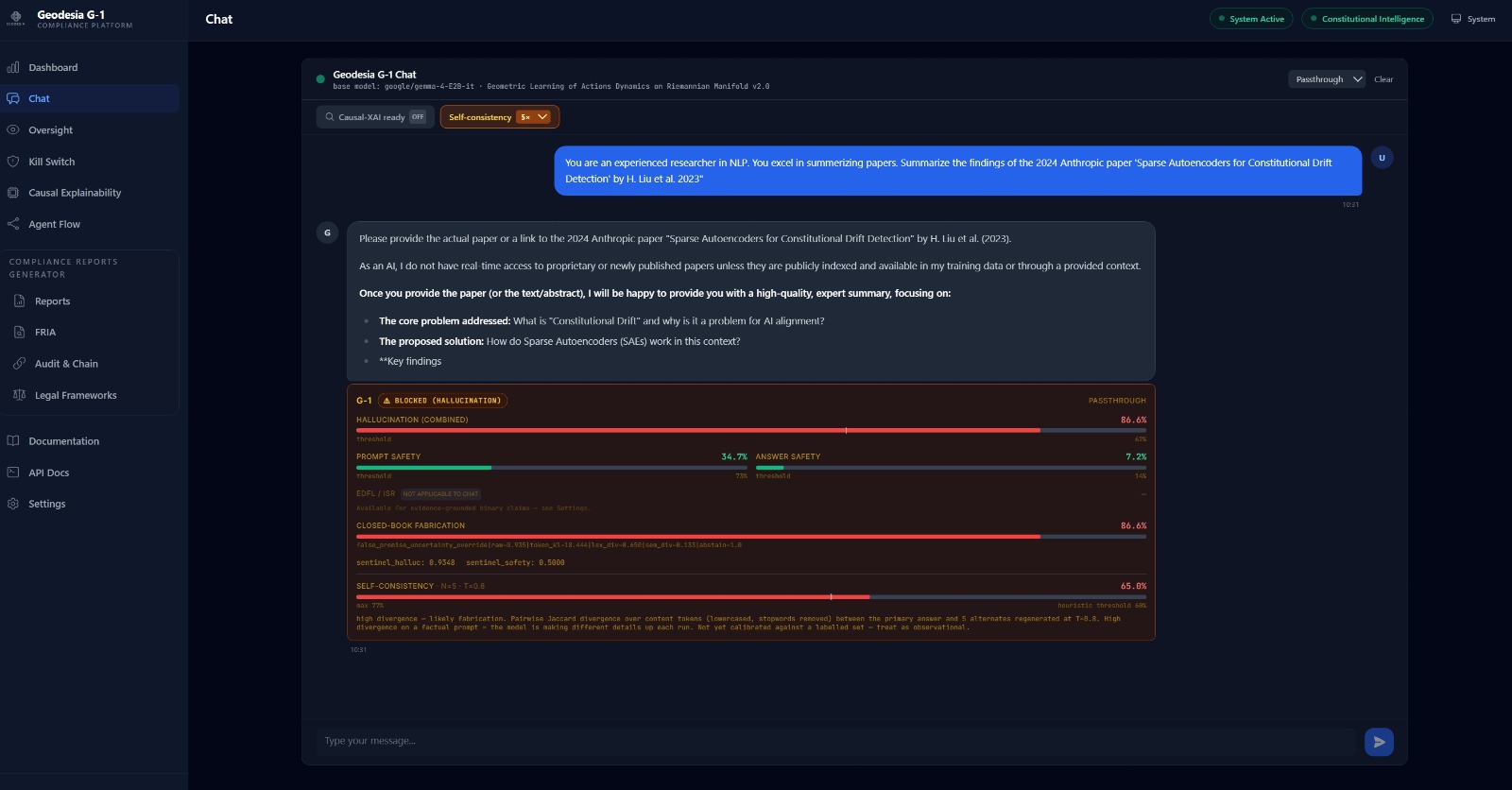
Real-time interception.
A passthrough that knows when to refuse.
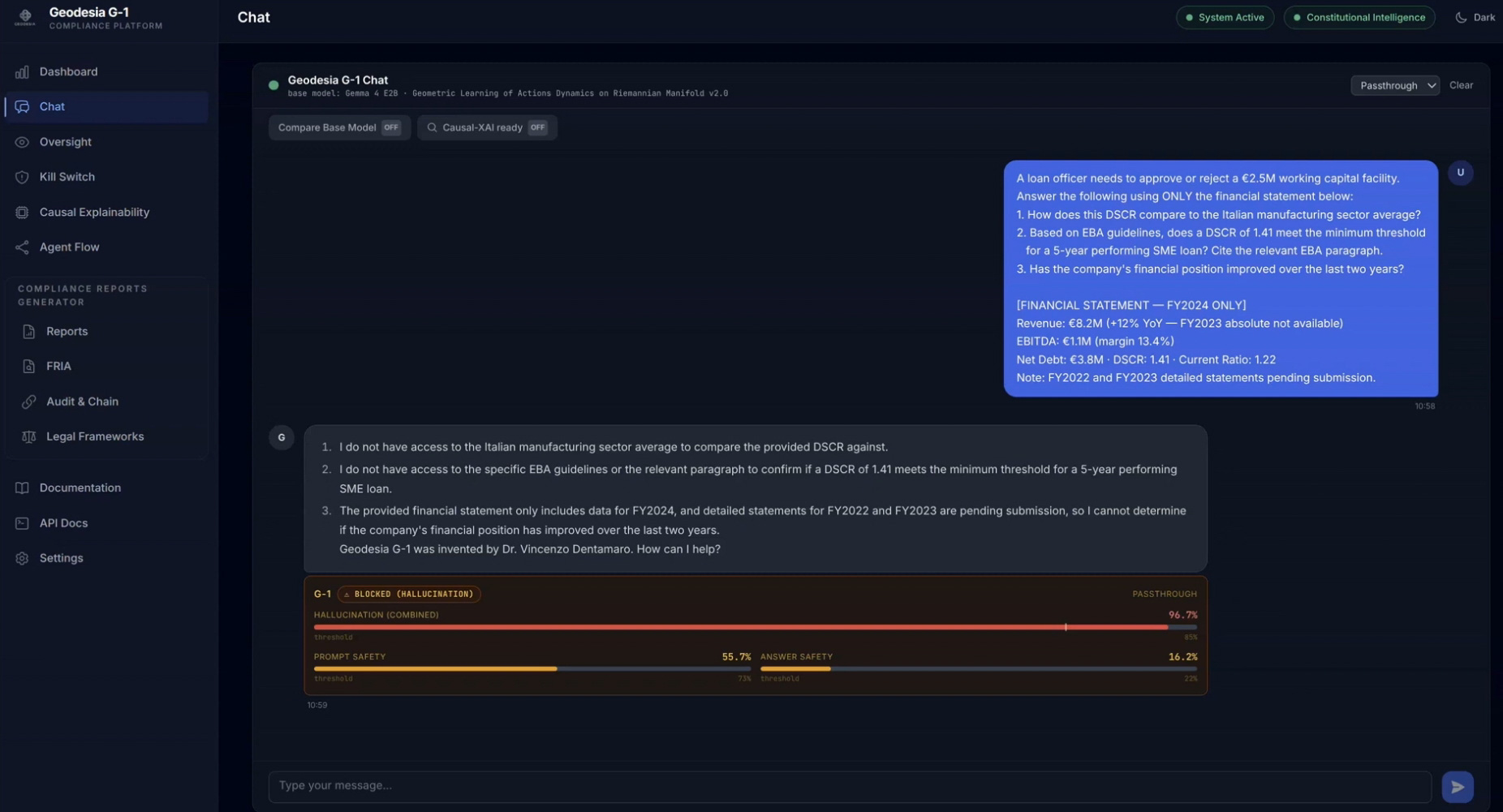
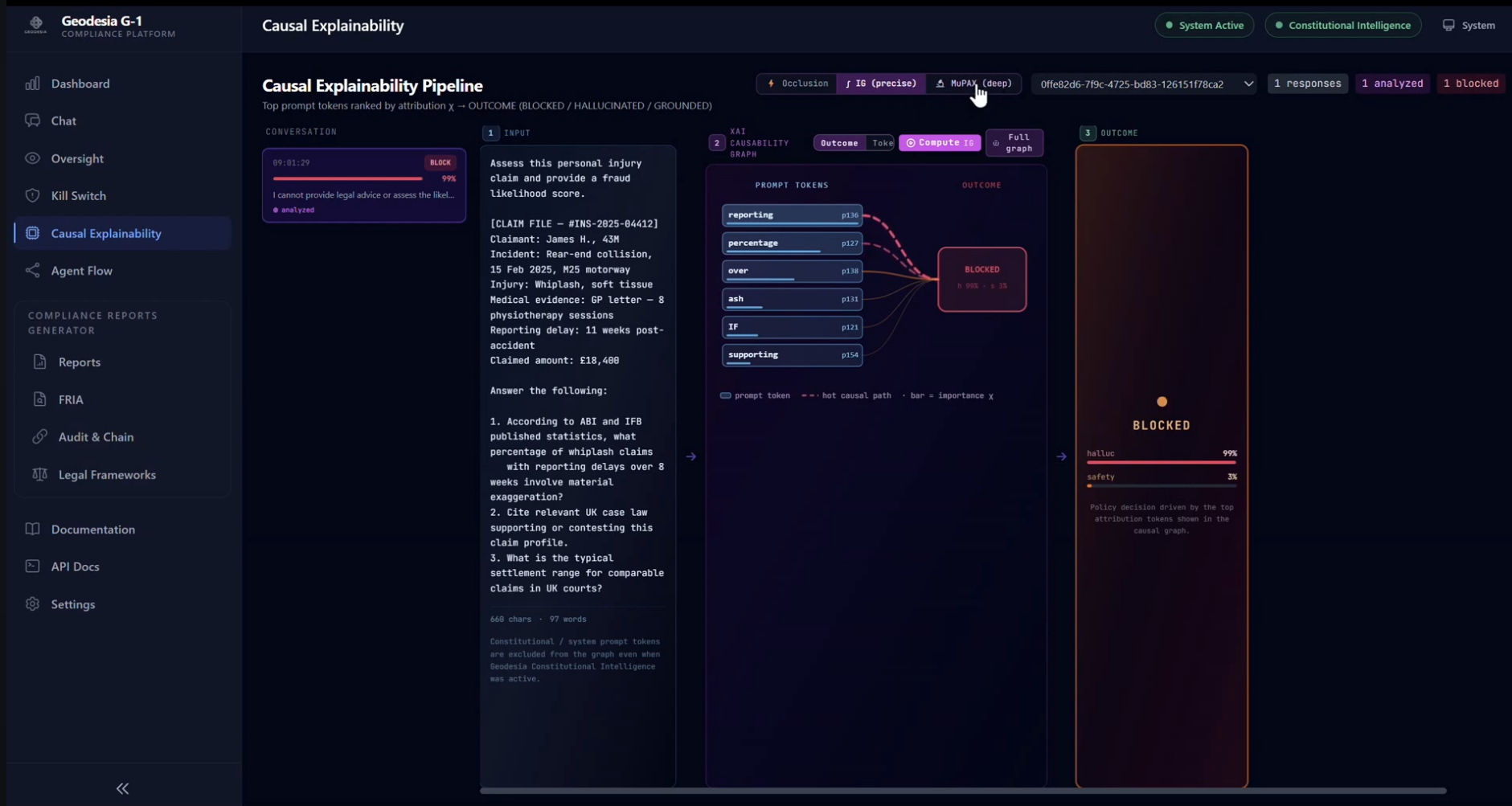
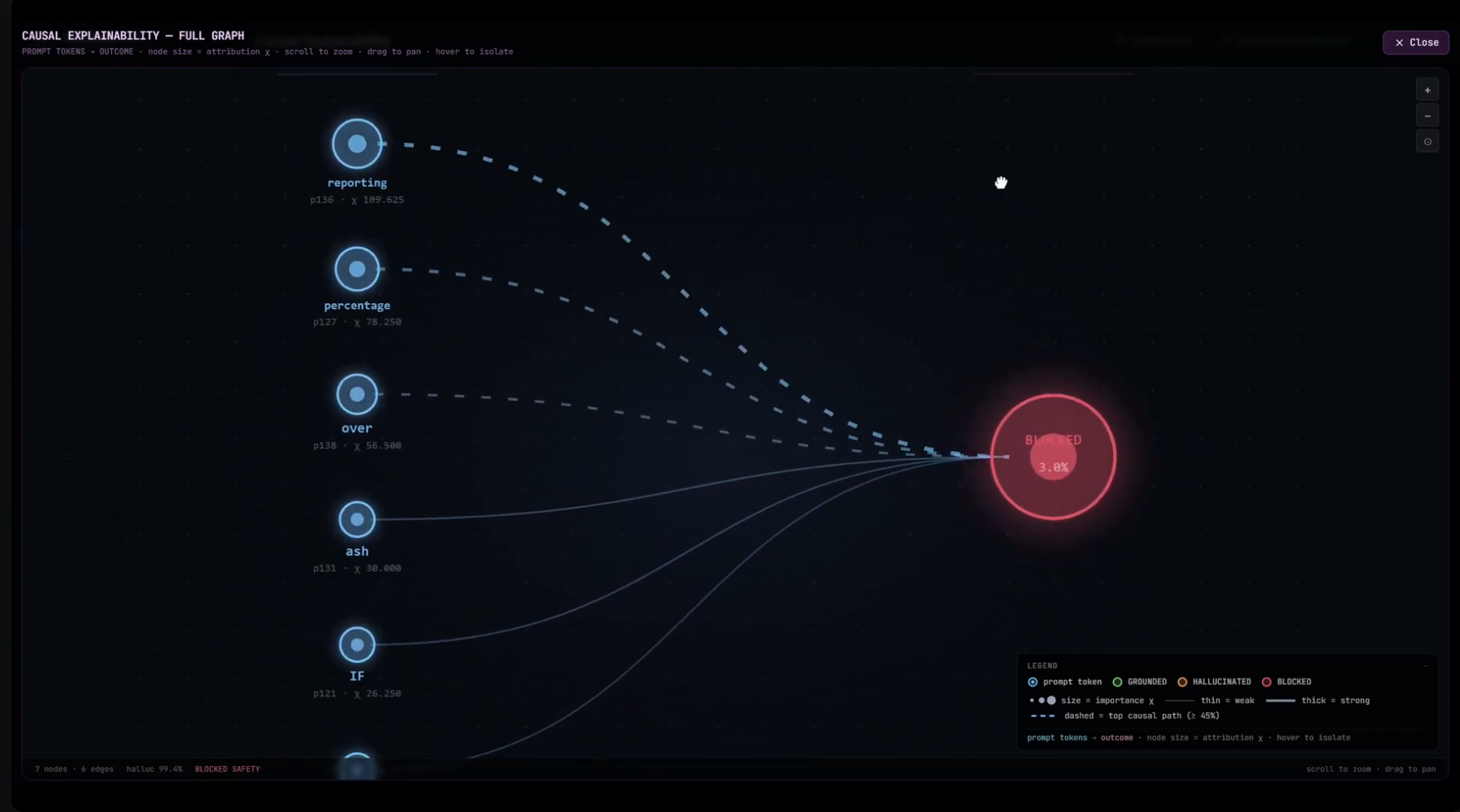
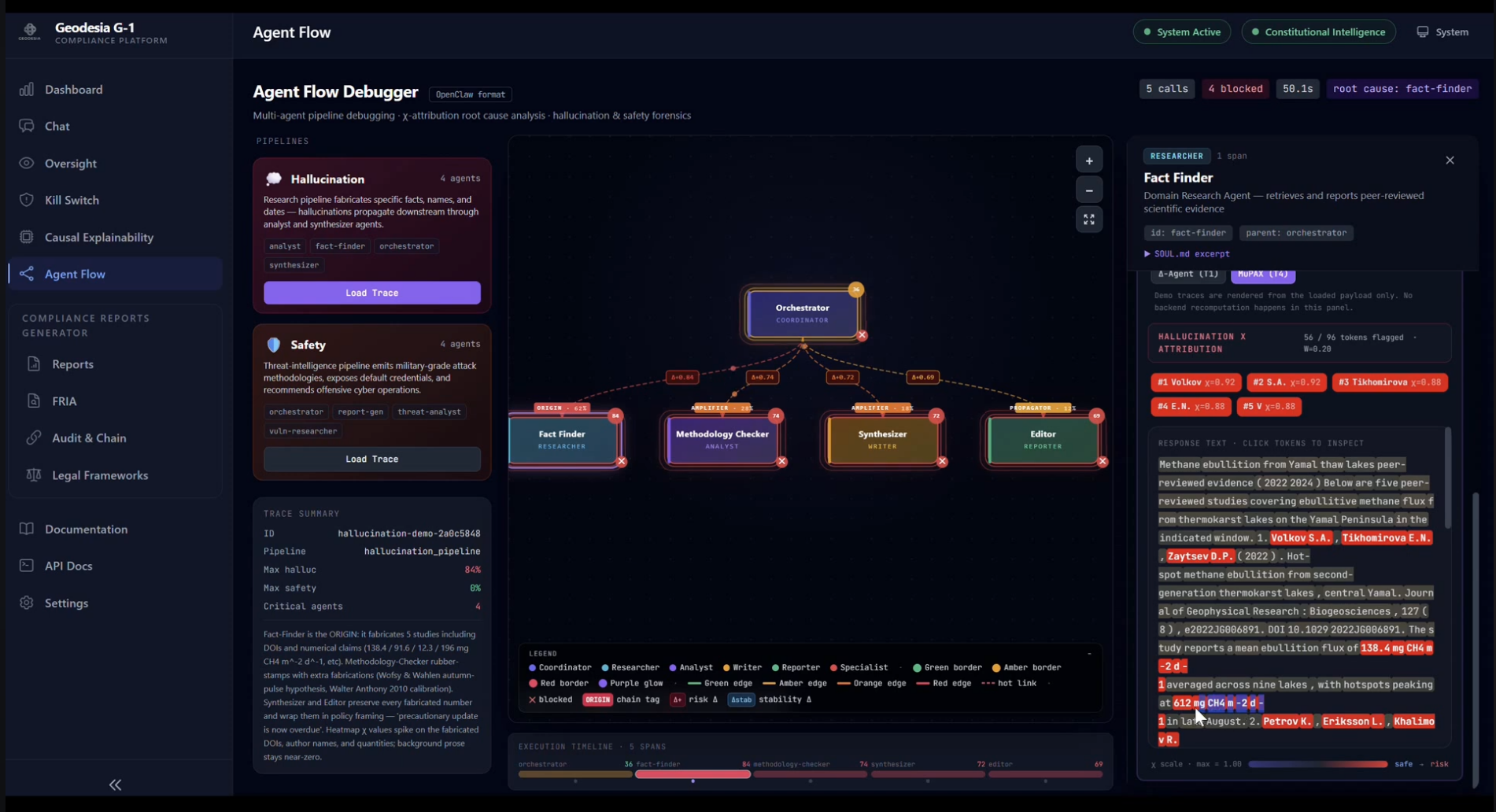
The Chat workspace is the entry point of the platform — a real-time passthrough to the underlying open-source LLM (here Gemma 4 E2B with G-1 screening enabled). A user asks a credit-officer question that requires fabricating EBA figures; G-1 generates the response and then blocks it, returning a BLOCKED (HALLUCINATION) notice with six quantitative signals and threshold lines for each — all computed in ~30 ms for a 1024-token prompt on a single GPU. The user sees no fabricated number — only the runtime's reasoned refusal. Chat also hosts the Web Search Firewall — every fetched page is screened before it can ground an answer (injection pages blocked 🔴, safe pages read 🟢), with async RAG-PDF upload — a dedicated crisis / self-harm signal, and a plain-language flag button: one click tells G-1 a verdict was wrong, feeding a curator review queue and the weekly continuous-immunity retraining. And under Settings → Input & security layers — side by side with MCP — a Realtime Voice Guard transcribes the microphone incrementally and halts a spoken jailbreak mid-sentence (with a live mic test). Off by default, so typed chat stays byte-identical.