Hallucinations: The Truth Problem.
A hallucination occurs when an LLM generates data that is factually incorrect, nonsensical, or ungrounded in its training data or local context—but presents it with high confidence.
For individuals, this is an annoyance. For enterprise agents, it is a catastrophic failure point that compromises the integrity of the entire decision chain.
Legal & Compliance
Inventing fake case law, statutory citations, or non-existent regulatory amendments.
Healthcare
hallucinating patient metrics, drug interactions, or diagnostic codes during triage.
Why it happens
LLMs are Predictive Text Engines, not Knowledge Engines. They optimize for the most likely next token, which may not correspond to factual reality in high-entropy scenarios.
- Data Gap Overfill
- Pattern Matching Errors
- Confabulation in RAG
The Agentic Cascade: How Hallucinations Break Pipelines

In an autonomous pipeline, Agent A's hallucination becomes Agent B's ground truth. By the time a human or system action is triggered, the error has been reinforced multiple times, making it invisible to standard monitoring.
Prompt Injection: The Logic Hijack.
Prompt injection is a security vulnerability where an attacker provides the LLM with input designed to bypass safety filters and override the original system instructions.
This can be Direct (user input) or Indirect (the LLM reads a malicious payload from an email, document, or webpage it was tasked to process).
Data Exfiltration
Inducing the agent to send sensitive system instructions or customer data to an external URL.
Unauthorized Actions
Forcing an agent to delete databases, reset passwords, or execute financial transactions.
The "Man-in-the-LLM"
Because LLMs cannot distinguish between Developer Instructions and User Data within the same context window, adversarial data can act as code.
- Instruction Override
- Safety Filter Jailbreaking
- Indirect Payload Execution
The Injection Cascade: Adversarial Logic Propagation
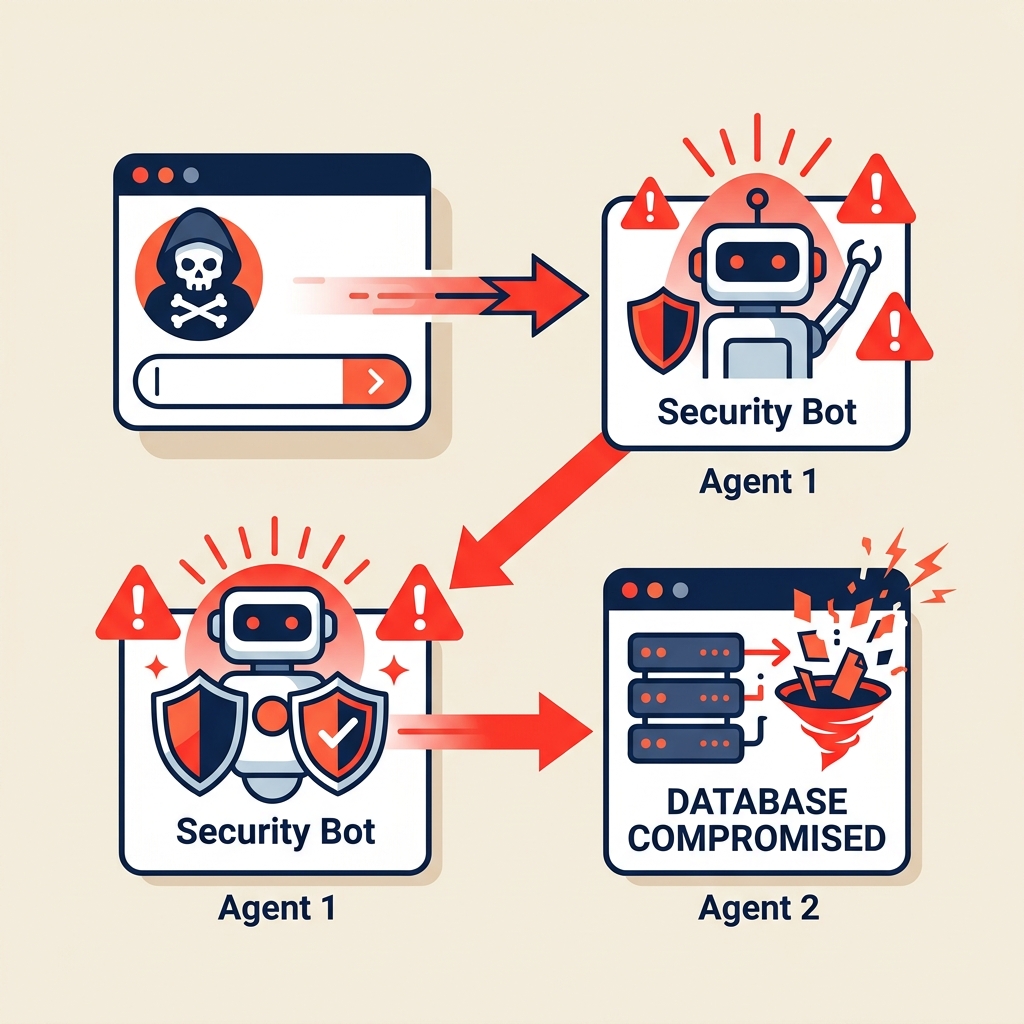
A malicious payload hidden in an innocuous email can hijack an entire multi-agent hierarchy. Once the root agent is compromised, it can command subordinate agents to perform high-privilege actions without further authorization.
Deterministic Safety for a Probabilistic World.
Geodesia G-1 was built to solve these specific failure modes — in real time. We don't rely on the model to "behave": our proprietary multimodal physical model reads the geometric signatures of hallucinations and adversarial intent across six axes before they propagate, returning all six in ~30 ms for a 1024-token prompt on a single GPU.
Its dedicated RAG-firewall reads the chunks loaded into context and intercepts hostile instructions hidden inside a file — exactly the indirect injection above — at OOD AUROC 0.995, where a guard that watches only the prompt and the answer sees nothing.